Our latest product update expands our classification and supplier processes to any user-created process.
CMTC has launched California's Sourcing & Procurement Platform (CSPP), a digital marketplace designed for manufacturers by manufacturers. This new supplier management platform is powered by Sustainment, a national marketplace that allows buyers and suppliers across the state and throughout the platform's network to securely connect and collaborate.
In our latest release, buyers can award businesses and upload a purchase order to share with their suppliers. After suppliers acknowledge the purchase order, they can provide essential information like quoted delivery date, price, terms and conditions, and other contract-specific elements.
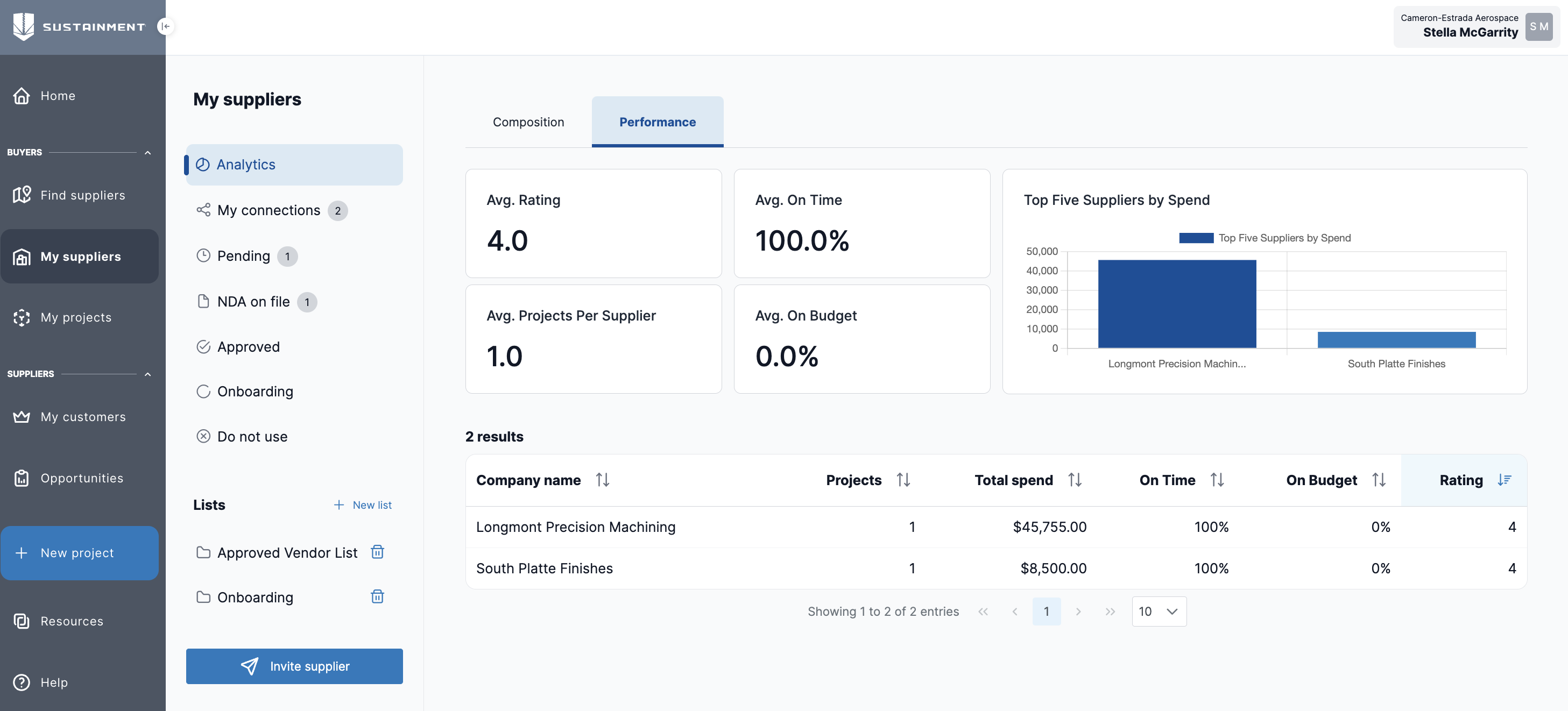
Sustainment's value focuses in helping you achieve your strategic goals with your supplier network. Recently, we launched Supplier Analytics, which gives you a view into your networks' composition and performance.
Manufacturer’s Edge Launches the Colorado Manufacturing Network Supporting the Manufacturing Industry Through the Sustainment Platform…
We believe that companies can be both profitable and purposeful. This belief is at the core of Sustainment’s decision to incorporate as a Public...
Sustainment’s journey to build more resilient and connected U.S. manufacturing supply chains reached an important milestone this month. I’m excited...
Incredible new companies and technologies are emerging in physical industries such as aerospace, transportation, power generation, and construction...
The content website and regional manufacturing newsletters from CompanyWeek will help facilitate Sustainment’s mission to showcase and connect ...
Partnership aims to give Texas manufacturing firms additional competitive advantage.
Sustainment, the software company transforming how business and government teams discover and engage with US manufacturers, today announced the...
The United States is a nation of builders. American renown is not a result of our prowess at financial engineering, legal sophistication, or...
Start for free with unlimited supplier management, up to 3 active projects and 5 users, then upgrade from $245/month.